

'WKSTNEQPMT' Table
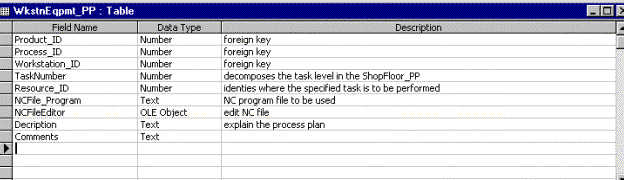
This forms the second table associated with storing information regarding the process plans associated with any product. A critical decision regarding database design, however, needs to be made at this level. The design proposed in this report stores all required information at the workstation and equipment levels in the same table. The alternative solution being separating the information into the workstation and equipment levels. Therefore, in the second design, each task mentioned in the workstation level will be exploded into its constituent tasks in the equipment level table.
In the first approach, the advantage offered by the design include the ability to verify the existence of the required NC program files at a particular equipment where the part needs to be sent, before actually sending the part to that equipment. This validation would prove to be useful when analyzing and controlling the system optimally, and employing alternate process plans. The disadvantage of this approach is that searching the table during simulation would require more comparisons of fields and records to sort through before any execution of a message. For example, in a particular process plan for a product, let us assume that at a particular stage, the product needs to have three operations in a piece of equipment in consecutive order. The database would contain three records to store this information, each of the records having exactly the same values for the product and process plan identifiers, workstation, and equipment identifiers. The difference would be in the task numbers and possibly the NC programs required for that operation.
In the second approach, the splitting of the database would potentially enable the equipment level controllers to be more responsible in obtaining the necessary information for executing the required operations. This, however, would duplicate some information regarding the product and process plan identifiers. The advantage being that the simulation would now require to access ‘smaller-sized’ tables for executing each SQL query. Data management, storage and debugging could be facilitated using this approach. However, the architecture of the Big_E may have to be altered to reflect a ‘three-tiered’ hierarchy.
The
Harold & Inge Marcus Department of
Industrial & Manufacturing Engineering
310 Leonhard Building
University Park, PA 16802